How do you design a high-available, scalable, secure and cost-efficient platform on AWS


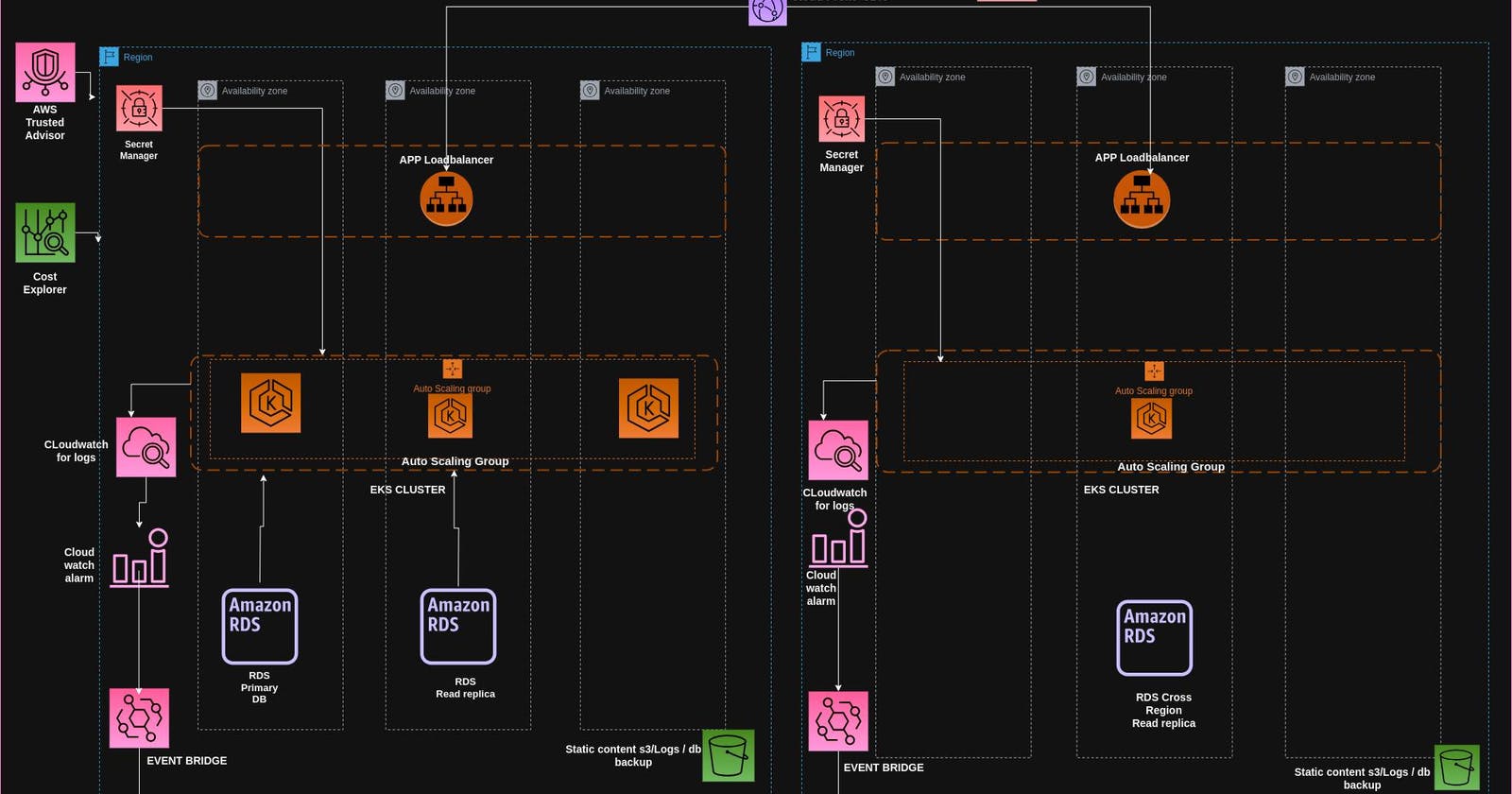
Table of contents
- Application Architecture Overview
- TOOLS And Technologies
- 1) High Availability and Scalability with Amazon EKS
- 2) Multi-AZ Deployment for Resilience
- 3) Cross-Region Redundancy
- 4) Traffic Routing and Failover
- 5) Service Exposure and Load Balancing
- 6) Security
- 7) Database Strategy
- 8) Monitoring and Alerting
- 9) Data Storage and Content Delivery
- 10) Content Delivery
- 11) Cost Optimization:
- 12 Infrastructure On AWS:
- 13) Kubernetes Deployment Files:
- 14 ) Continuous integration continuous delivery or Deployment (CICD)
Application Architecture Overview
TOOLS And Technologies
AWS : EKS ,Route53 ,RDS multi-region, AWS secret manager , AWS Certificates manager(ACM), Cloudwatch , S3, CloudFront(CDN), Cost Explorer, Trusted Advisor
IAC: Terraform
CICD: Gitlab and ArgoCD
Package Manager: Helm
Version Control System: Gitlab
Containerization and orchestration: Docker and Kubernetes (EKS) , Isto Service Mesh
Microservices Architecture:
I Will be utilizing microservices architecture for my application which enables us to have independent scalability, fault isolation, and easier maintenance. Use containerization (e.g., Docker) for packaging applications and their dependencies. for container orchestration, I am using Kubernetes (AWS EKS)
1) High Availability and Scalability with Amazon EKS
To achieve High Availability and Scalability I am utilizing Amazon EKS to host my application, harnessing its ability to dynamically scale based on traffic fluctuations. As traffic volume surges, I've configured the EKS cluster to seamlessly engage the AWS Auto Scaling service. This setup triggers the creation of new worker nodes when the CPU or memory utilization of the nodes hits the 70% threshold. Consequently, during periods of reduced traffic, any surplus nodes are automatically decommissioned. This synergy between Amazon EKS and AWS Auto Scaling guarantees efficient resource employment and cost-effectiveness.
2) Multi-AZ Deployment for Resilience
I am Deploying my EKS cluster across multiple Availability Zones (AZs) which enhances resilience. In the event of AZ failure, Our application remains available, reducing downtime and ensuring continuous service to End users.
3) Cross-Region Redundancy
By deploying our infrastructure in two regions, We establish a region-resilient architecture. The primary region hosts full-fledged infrastructure, while the secondary region contains minimal infrastructure. If the primary region becomes unavailable, traffic can be redirected to the secondary region using Amazon Route 53.
4) Traffic Routing and Failover
Amazon Route 53 for DNS Failover
Utilizing Amazon Route 53's DNS failover capability allows for seamless traffic rerouting from the primary region to the secondary region in case of a failure. By adjusting DNS records, We can ensure uninterrupted access to our application.
5) Service Exposure and Load Balancing
Istio Service Mesh for Exposing Applications to End User
am utilizing the Istio service mesh within my cluster to manage control and observability for microservices, handling traffic, security, and communication patterns. Istio offers fine-grained routing, retries, load balancing, and fault tolerance, enhancing resilience and minimizing downtime. It also provides features like traffic splitting and timeouts for A/B testing. With its mesh-wide capabilities, Istio improves service-to-service communication, security, and monitoring. Additionally, we expose our application using the Istio Ingress Gateway service.
6) Security
AWS Secrets Manager for Secret Management
I am leveraging AWS Secrets Manager which provides a robust and secure solution for effectively managing application secrets, such as database credentials and sensitive information like passwords. This service ensures meticulous access controls and encryption mechanisms, thus significantly enhancing the overall security posture of our application.
To ensure secure connections, I have implemented AWS Certificate Manager (ACM) to provide TLS certificates for our domain. This approach not only establishes a trusted encryption layer but also further fortifies the security infrastructure of our application. By combining AWS Secrets Manager and ACM, we reinforce the protection of sensitive data and communications, aligning with best practices in security management.
7) Database Strategy
Amazon RDS with Cross-Region Read Replica
I am currently employing Amazon RDS, incorporating cross-region read replicas to ensure both data availability and disaster recovery. This configuration not only guarantees high availability but also establishes data redundancy across regions, offering a protective measure against potential data loss. An illustrative instance of its effectiveness occurred a few months ago when the AWS us-east-1 region experienced downtime, impacting numerous organizations that hadn't implemented cross-region replication.
8) Monitoring and Alerting
CloudWatch for Monitoring and Alerting
CloudWatch is used for monitoring various aspects of our application's performance. We create Dashboards that provide visual insights to our application trends,also using cloud watch alarms which are triggered for specific metrics. These notifications can be routed through EventBridge to platforms like Slack or email.
9) Data Storage and Content Delivery
Amazon S3 for Data Storage and Backup
I utilize Amazon S3 as a versatile object storage solution for static content, database backups, and log backups. This service provides durable and scalable object storage, guaranteeing dependable data retention.
We intend to configure an S3 lifecycle policy that will automatically transition objects from the standard storage tier to other storage tiers. This strategic move will assist us in reducing storage costs.
10) Content Delivery
Amazon CloudFront for Content Delivery
I am using Amazon CloudFront to efficiently deliver static content to users. It acts as a content delivery network (CDN), reducing latency and enhancing user experience.
11) Cost Optimization:
While I've already taken into account cost efficiency in my architecture by implementing scaling and resource management strategies, I'm considering a more proactive approach. I'm integrating AWS Cost Explorer and Trusted Advisor to better identify continuous opportunities for cost-saving. Leveraging Graviton instances and gp3 volumes on AWS offers substantial cost savings while maintaining performance. Graviton instances deliver a competitive price-to-performance ratio, catering to optimized workloads and minimizing licensing expenses gp3 volumes, a type of Amazon EBS storage, provide cost-effective IOPS provisioning, Graviton2 instances demonstrate comparable or better performance than x86 counterparts at lower costs. AWS reports up to 20% reduced costs with Graviton instances Incorporating these options can lead to significant cost savings without compromising application performance.
12 Infrastructure On AWS:
To establish the entire infrastructure on AWS, I've embraced the concept of Infrastructure as Code (IAC) through the use of Terraform. This approach holds significant advantages, as manual creation of resources on AWS is not only time-consuming but also prone to errors. With Terraform, I can define and manage my infrastructure as code, automating the deployment process and ensuring consistency and accuracy.
One of the notable benefits of using IAC is its reusability. By encapsulating infrastructure configurations within code, I can easily replicate and reuse these configurations across multiple environments and projects. This not only enhances efficiency but also promotes consistency and reduces the chances of configuration discrepancies between different deployments.
13) Kubernetes Deployment Files:
In orchestrating the deployment of our application, I've chosen to leverage Helm charts. These charts serve as comprehensive templates, encompassing not only the application deployment service but also a range of Kubernetes resources. One of the key advantages of Helm lies in its ability to dynamically inject required values from dedicated values.yaml file during the deployment process. This dynamic value injection at runtime ensures a tailored and adaptable deployment.
The decision to use Helm is driven by its reusability across various deployments. By crafting a Helm chart, we establish a standardized blueprint for our application's deployment, which can be conveniently reused across different scenarios. To deploy the same chart with distinct configurations, we only need to modify the values within the values.yaml file, thereby simplifying the process and enhancing consistency across deployments.
14 ) Continuous integration continuous delivery or Deployment (CICD)
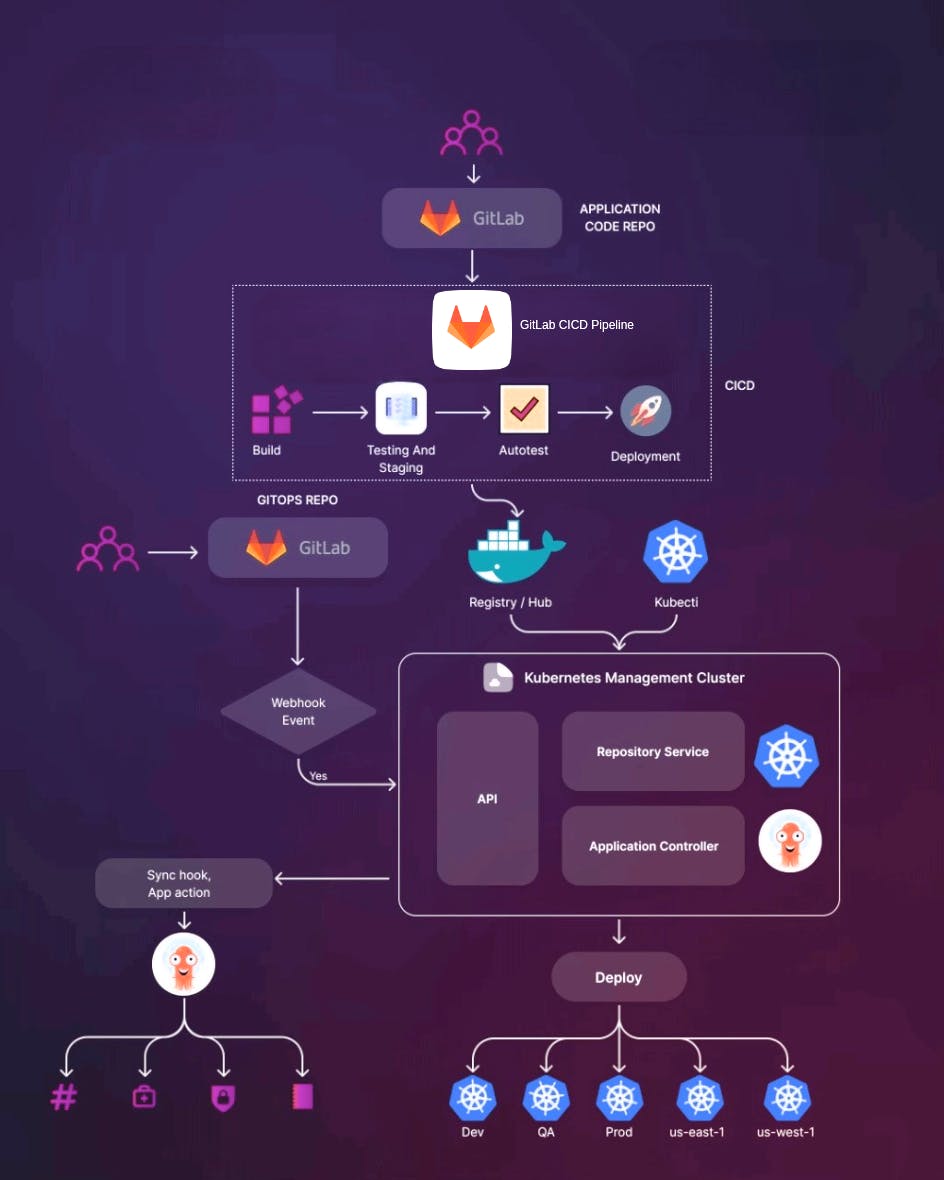
I've chosen GitLab as my Version Control System (VCS) for source code management due to its robust features. GitLab enables seamless collaboration among developers by maintaining source code and providing version control. This platform streamlines the development process, allowing efficient tracking of code changes and facilitating collaborative efforts.
Branches Strategies: I am using a feature branch strategy for isolating changes and features.
Pull Requests: Mechanism for proposing, reviewing, and merging code changes.
Code Checkout :
In the initial stage of my CI process, I initiate by fetching the source code from the GitLab repository where developers commit their code. This step ensures the synchronization of the latest code changes.
Following that, the code undergoes compilation, aiming to detect and rectify any potential compilation errors.
static Code analysis
Moving on to the second stage of the CI process, I focus on conducting static code analysis. This pivotal software validation procedure involves scrutinizing the source code for quality, reliability, and security aspects, all without actual code execution.
By employing SonarQube as the tool of choice for static analysis I can effectively pinpoint defects and security vulnerabilities that have the potential to jeopardize the overall integrity and safety of my application. This proactive approach ensures that issues are addressed early in the development lifecycle So the developer can fix the issue in an early stage.
Testing:
Testing is a pivotal aspect of the development process, providing a strong guarantee of the intended functionality within the codebase. Unit testing meticulously isolates individual units of code, ensuring that their behaviour aligns with expectations and validating their accuracy. However, the testing process doesn't stop here. It extends to encompass a comprehensive strategy that includes integration testing, functional testing etc. This comprehensive approach works in harmony to deliver a thorough validation of the software's reliability, functionality, and performance across a spectrum of dimensions, ensuring a robust and dependable end product.
Docker Image Build and Push:
In this stage of our CI pipeline, we create a Docker image of our codebase, encapsulating our application's environment and dependencies. When considering the choice of the image registry, we've opted for Amazon Elastic Container Registry (ECR) over Docker Hub. This decision is motivated by ECR's seamless integration with the AWS ecosystem, offering enhanced security, scalability, and accessibility, especially if our application operates within an AWS environment.After Building the Docker Image we then push it to the chosen registry which is AWS ECR.
Scanning Image and updating helm chart:
Once the build process is completed and the Docker image is successfully pushed to the Amazon ECR registry, the next vital step involves meticulous image scanning. I initiate a comprehensive scan to identify potential vulnerabilities, security risks, and deprecated packages within the image. This diligent scanning process enables me to proactively address any vulnerabilities and risks before they become security concerns. Subsequently, I take proactive measures to remediate the identified issues, ensuring the image's robust security posture.
Subsequently, I incorporated the new version of our Docker image into the Helm chart's value.yaml file, a task efficiently handled by a custom script. This ensures a seamless transition to the updated Docker image within our application deployment helm chart.
15) Application Deployment To EKS Cluster:
In the context of advancing our deployment process, I've adopted the GitOps methodology to orchestrate application updates. GitOps is an approach that leverages version control systems, like Git, as the single source of truth for infrastructure and application configurations. This methodology ensures that any changes made are captured in the version control system, providing a reliable audit trail of modifications.
For implementing GitOps, I've opted for the ArgoCD tool, which effectively monitors changes within deployment files and synchronizes them with the cluster, maintaining alignment between the desired state and the actual state of our application.
To manage the deployment strategy, I've chosen the Canary deploying strategy. This strategy involves rolling out new application versions alongside stable, production versions. It allows for gradual testing and validation of the new version's performance, ensuring a smoother transition and minimizing potential disruptions. This dual-pronged approach of GitOps and the Canary deployment strategy underscores a commitment to seamless, controlled, and reliable application updates.